今回はscansnapで本を頑張って自炊した後のデータの手入れ方法について説明します。
「そのまま普通に電子書籍として読んだらダメなの?」
と思うかもしれませんが、出来なくはないけど、ファイルサイズが重いので、ファイルを最適化する必要があります。
具体的には「adobe abrobat」を使って「OCR認識」と「ファイルの最適化をする」のがベストです。
今回はそのやり方を説明します。
ちなみに本を電子化するための方法はこちら、電子化した本が読めるオススメのアプリはこちらで詳しく説明しています。
目次
電子化(自炊)した本を最適化するためにやること
- OCR認識・・・画像をテキスト化して検索出来るようにする
- ファイルの最適化・・・pdfの不要なデータを削除したり圧縮して容量を減らす
注意点としてはOCR認識に完璧さを期待しないほうが良いです。
この設定をしてもガッツリ1枚ごと画像なこともよくあるので。
メインの目的としては「ファイルの容量を減らす」。ついでに「テキストで検索できたらいいなあ」ぐらいで考えてください。
使うソフトはadobe acrobatがオススメです。基本は有料ですが、scansnapを購入すればソフトもついてくるので、実質無料で使えます。
※電子化(自炊)したい本が少ない人には
ちなみにこの記事は電子化したい本が10冊以上のような方向けになります。
正直設定がめんどくさかったりするので、「簡単にファイルサイズを減らせればそれで良い」という人は、下記のサイトにpdfをドラッグ&ドロップすれば圧縮されたpdfがゲット出来るので、こちらを使ったほうが簡単です。
1.ファイルをadobe acrobatで開いて、アクションウィザードを開く
高城さんの「モノを捨てよ、世界へ出よう」というドンピシャな本を今回は電子化しました笑
右の欄からアクションウィザードを探して選択するか、検索して見つけます。
アクションウィザードとは簡単に言うと「色んなpdfをいじる設定を保存して、それを複数のファイルに使えるもの」なので、自炊したデータが40や50個とかある人にとってはかなり楽になるので、是非使ったほうが良いです。
2.新規でアクションを作り、「テキスト認識」の「OCRを使用してテキストを認識」をアクションに追加する
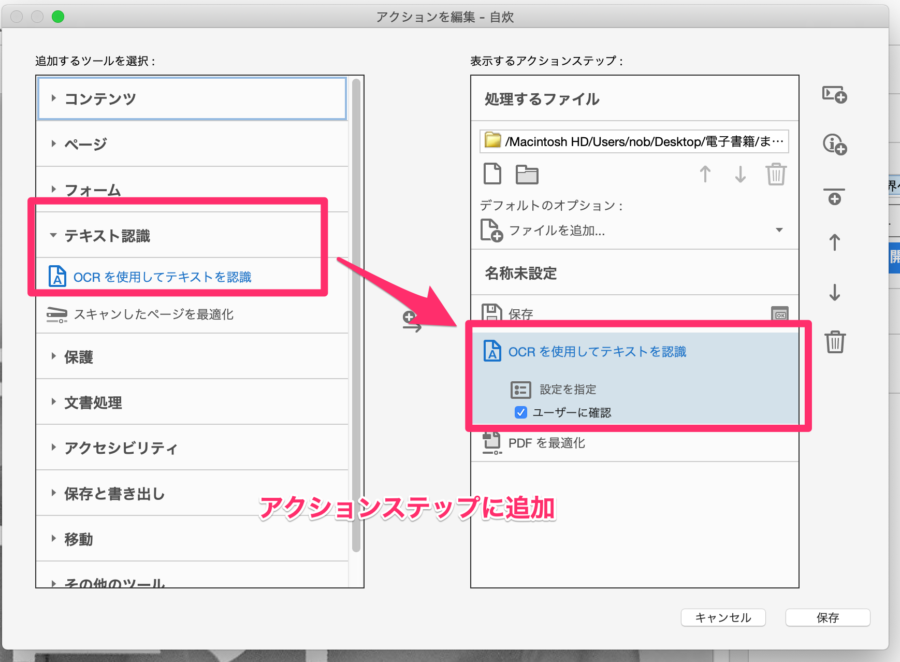
「テキスト認識」の「OCRを使用してテキストを認識」をアクションに追加します。
※「ユーザーに確認」のチェックはいちいちファイル毎に聞いてくるので、これは外しておいたほうが良いです。
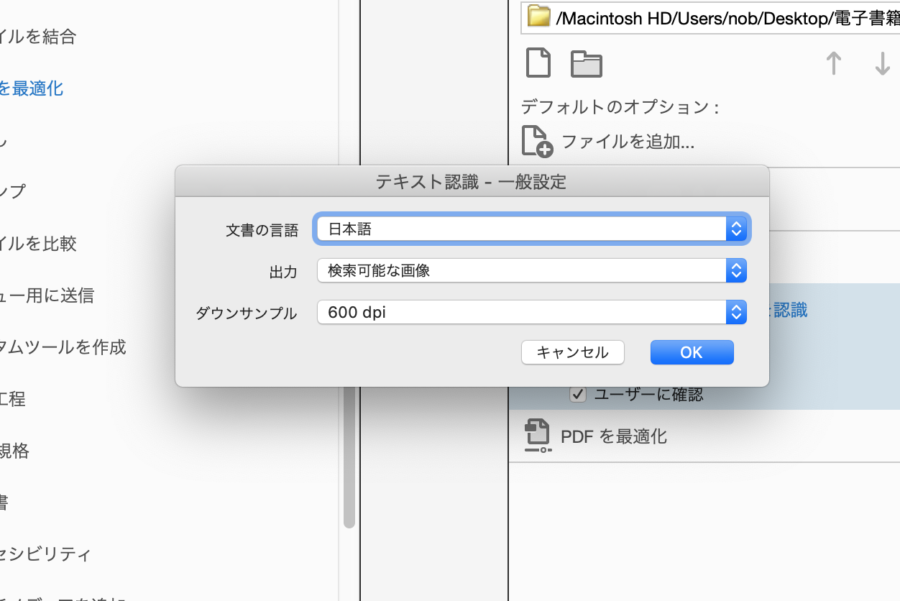
「設定を指定」をクリックするとこのような画面になるので、この通りで指定してください。
- 文章の言語:日本語
- 出力:検索可能な画像
- ダウンサンプリング:600dpi
3.保存時の設定を調整する

こちらの「保存」の部分をダブルクリックすると詳細を設定出来ます。

ファイル名は「_min」などをファイル名の最後につけるとかで良いでしょう。
そしてここで「pdfの最適化」も設定できるので、「設定」をクリック。
色んな設定がありますが、とりあえずこの通りにしておけば問題はないかと思います。
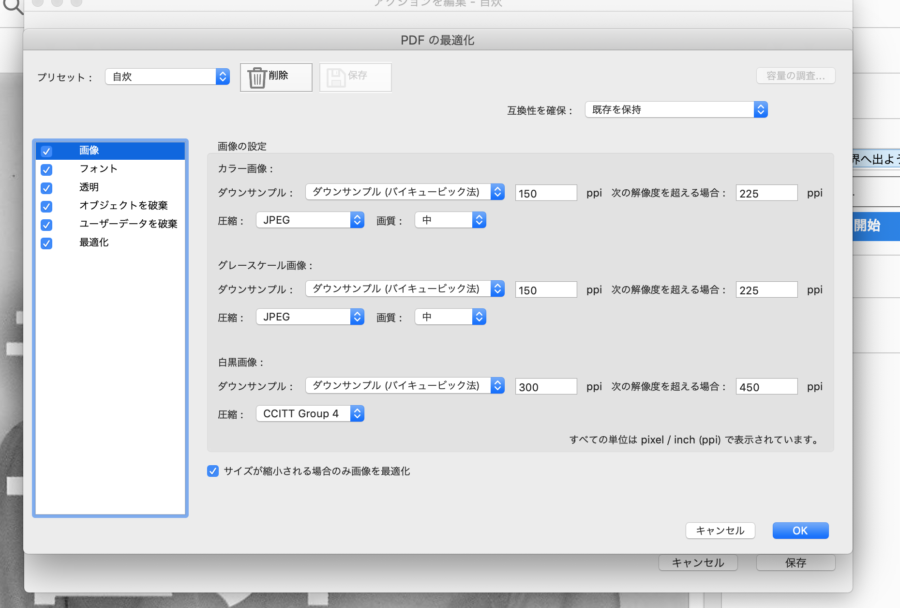
「pdfの最適化」の画像
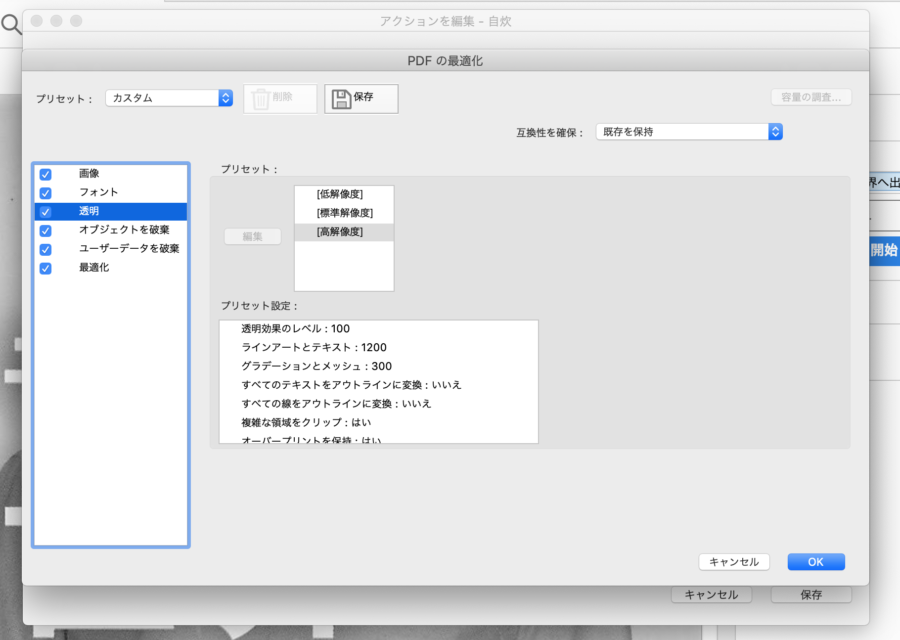
「pdfの最適化」の透明
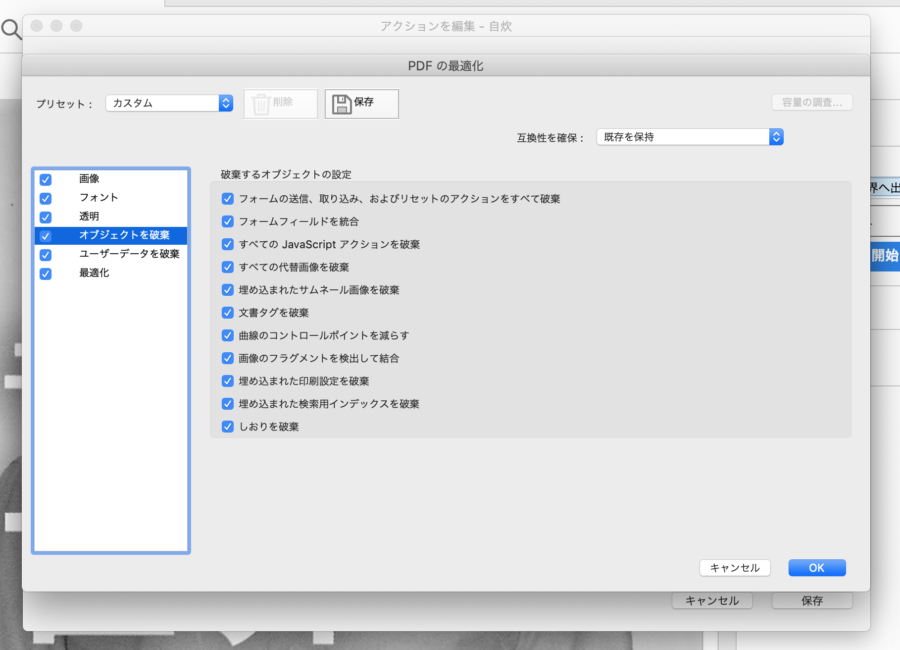
「pdfの最適化」のオブジェクトを破棄
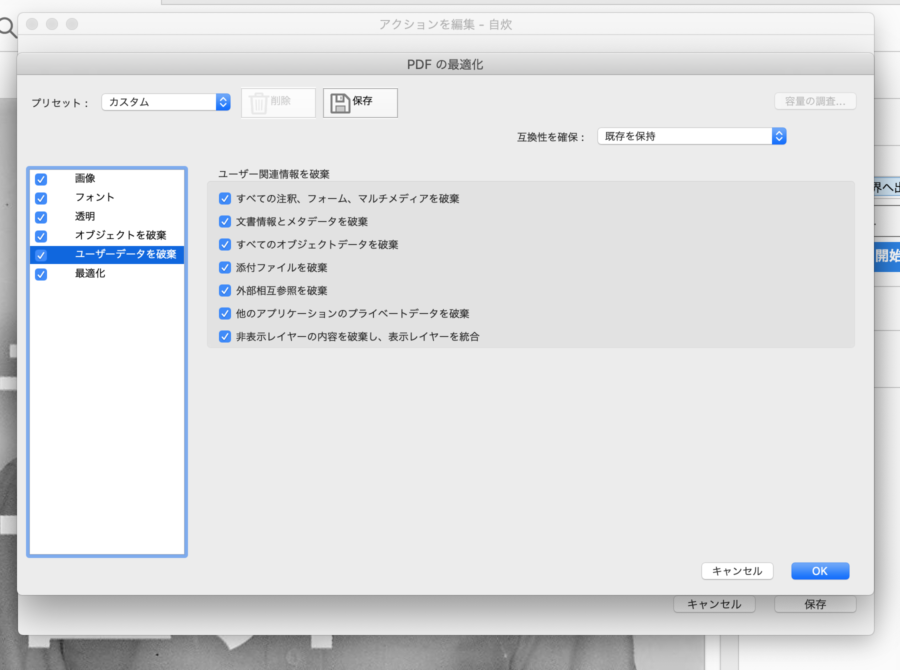
「pdfの最適化」のユーザーデータを破棄
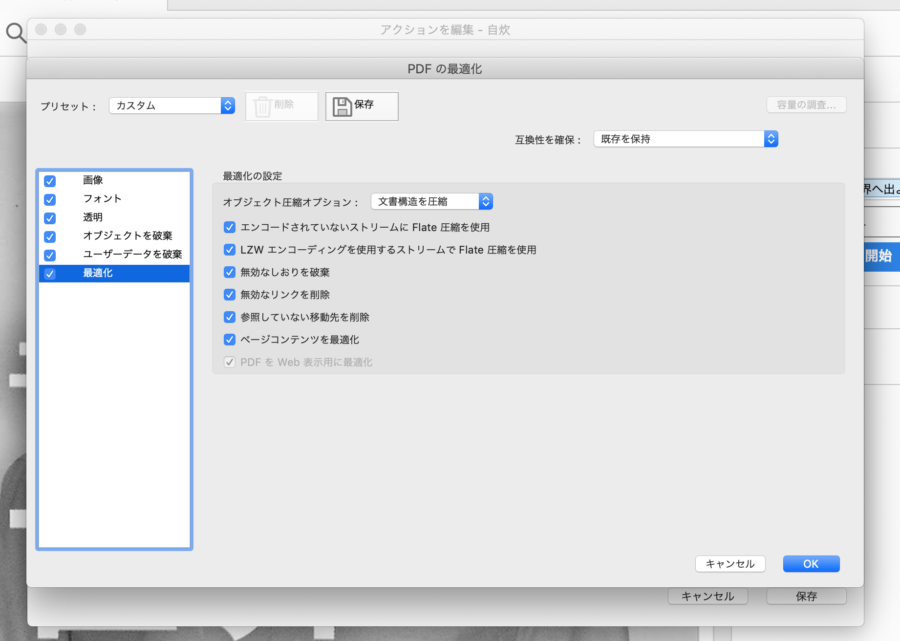
「pdfの最適化」の最適化
すべてが終わると、設定を保存します。
アクションウィザードの設定名は「自炊」などにしてわかりやすいようにしておきましょう。

5.アクションを保存して、実行

まず、一つのファイルだけ試してみましょう。全部やって失敗していたら大変めんどくさいので。
1つにつき5〜10分程度みたほうが良いです。
どのくらいファイルサイズを圧縮出来るのか?

なんと文庫本では80%も圧縮が出来ていました。他にも色々試してみた結果、
- 文庫・・・28.8MB→6MB(80%圧縮)
- 単行本・・・47.6MB→14.8MB(70%圧縮)
- 写真集・・・185.5MB→37.1MB(80%圧縮)
結果としては70〜80%程度圧縮が可能ということがわかりました。
見比べてみた

表紙の圧縮前と圧縮後

文章の圧縮前と圧縮後
個人的にはほとんど変わりは無いです、というかあんまり違いがわかりません。
何のアプリで見れば良い?
色々試しましたが、出来上がった電子書籍は「i文庫HD」で見るのが一番見やすいです。
これについてはまた詳しく解説します。

最後に
いかがでしょうか、参考になれば幸いです。
本を電子化するための方法はこちら、電子化した本が読めるオススメのアプリはこちらで詳しく説明しています。
コメントを残す